the Analytics Agent built for context engineering
Build your agent context like a file system.
Deploy a chat UI for anyone to run analytics on your data.
100% Open Source.
Exploring context: warehouse schema, metrics & models...
Ask anything about your data
Agent reliability depends on context. Engineer it.
Engineer your agent's context
Create your context like a file system
Create the file system context for your agent.
Add anything you want in the context: data, metadata, rules, docs, tools, MCPs. No limit.
project_name: nao-agent databases: - name: bigquery-prod accessors: - columns - description - preview - profiling include: - prod_silver.dim_users exclude: [] type: bigquery project_id: nao-production credentials_path: /path/to/credentials.json repos: - name: dbt url: https://github.com/dbt-repo.git notion: api_key: {{ env('NOTION_API_KEY') }} pages: - https://www.notion.so/naolabs/
Synchronize your existing context
Pull context from existing context sources automatically
















Measure your context reliability
Measure and monitor your context performance to improve it.
Create unit tests of questions to SQL and get instant metrics on context reliability and efficiency.
Deploy your agent to everyone
Deploy your agent with nao UI
Ask questions in plain English
Claire, what do you want to analyze?
Exploring context: warehouse schema, metrics & models...
Ask anything about your data
Create data stories
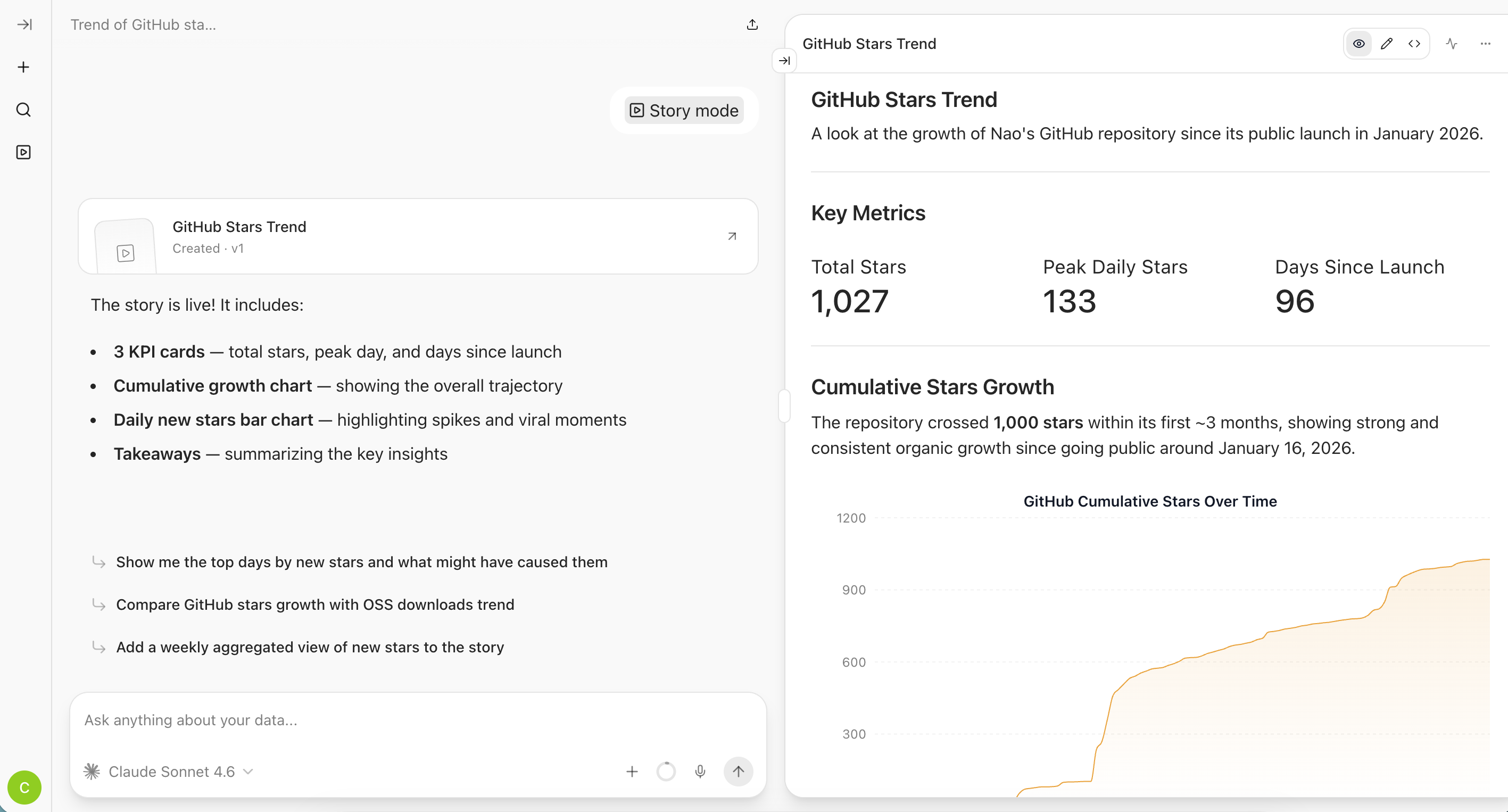
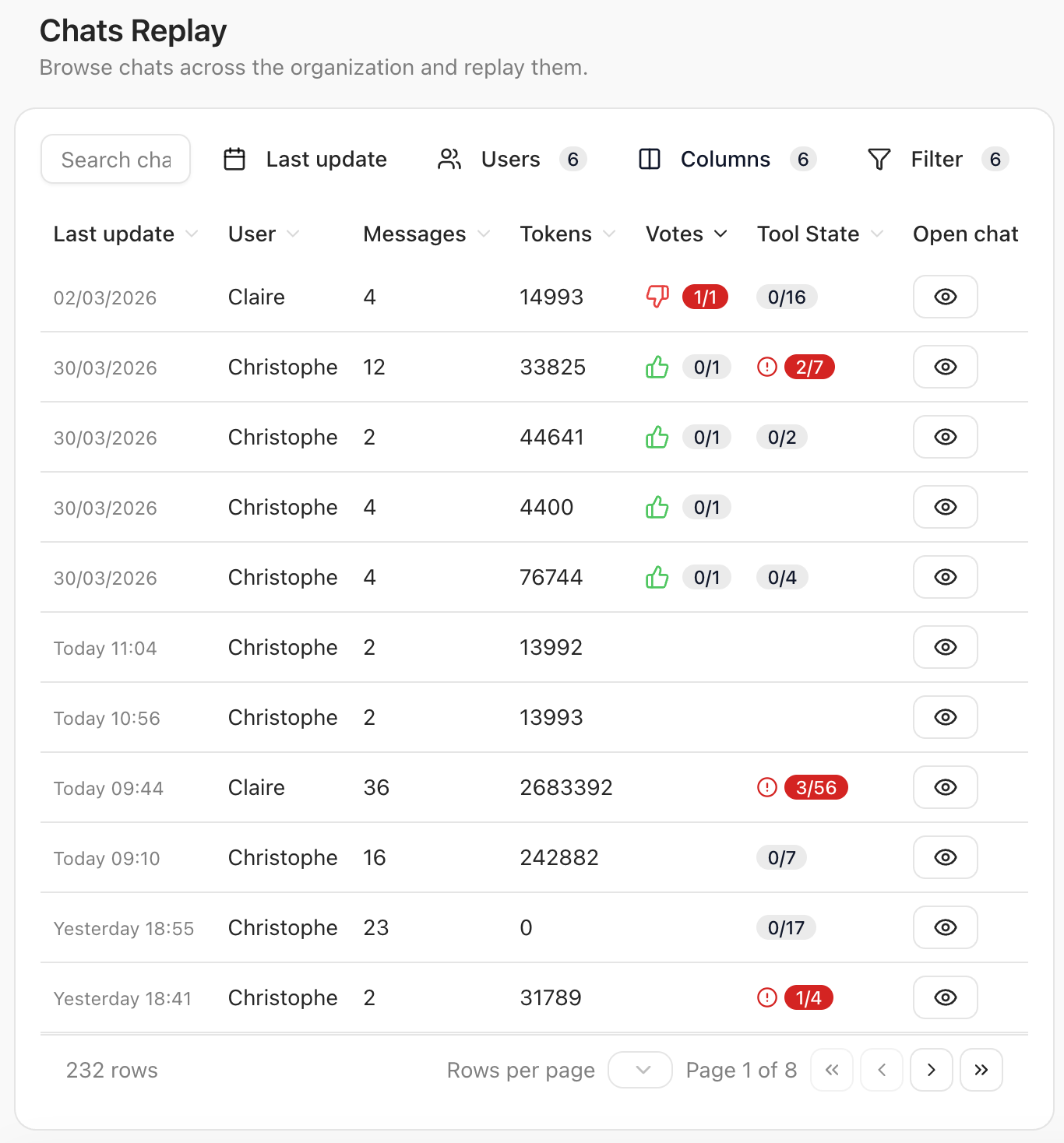
Monitor user chats
Bring your own key
Deploy a chat with your own LLM key.
Pay only token consumption.
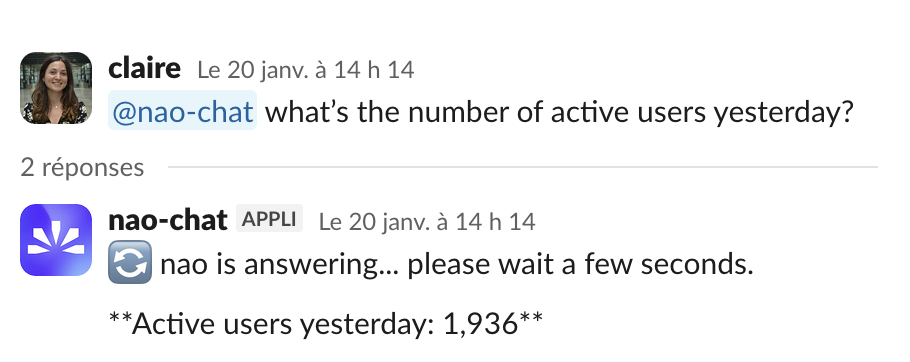
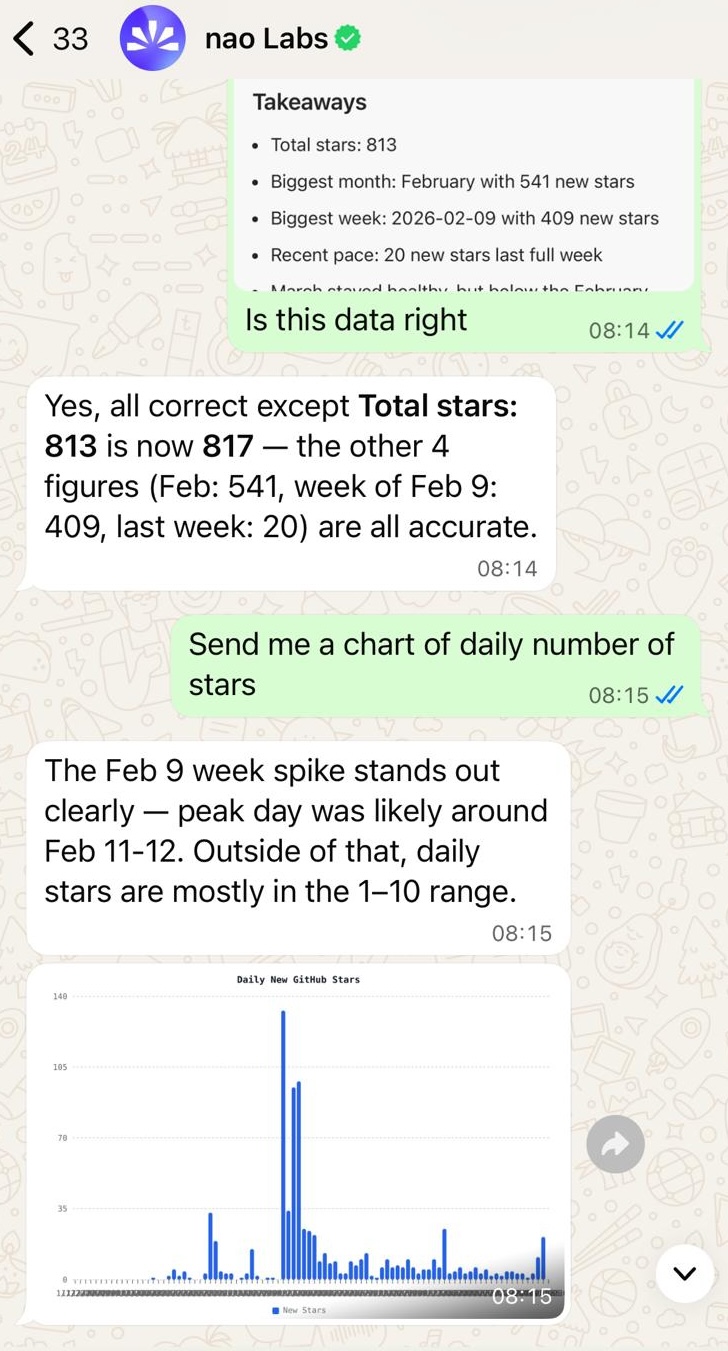
Ask questions in Slack, Teams, WhatsApp or Telegram
Self-host your agent
Self-host your analytics agent and use your own LLM keys to guarantee maximum security for your data.
Everything stays in your infrastructure, under your control.
Learn Context Engineering
Learn how to optimize your agent's context for best performance.
Optimize reliability with the right context, optimize efficiency with better context structure and modularity.
