How to choose the right data stack
A comprehensive guide to choosing the right data stack for your company's stage and data maturity.
5 October 2025
By ClaireCo-founder & CEOTable of contents
- Why the Modern Data Stack?
- The Core Components of a Modern Data Stack
- How to Assemble Your Data Stack
- Conclusion
- Frequently Asked Questions
Why the Modern Data Stack?
The Modern Data Stack (MDS) is a new, cloud-first way to work with data. Unlike old systems that were big and monolithic, it's modular - you pick the tools you need for collecting, transforming, and analyzing data.
If your data is mainly in the cloud, available through your internal data sources or via APIs for external data, the Modern Data Stack can help you move faster, scale easily, and plug in AI tools as you grow.
This guide walks you through the main components of a Modern Data Stack and helps you choose the right setup for your company's stage and data maturity.
The Core Components of a Modern Data Stack
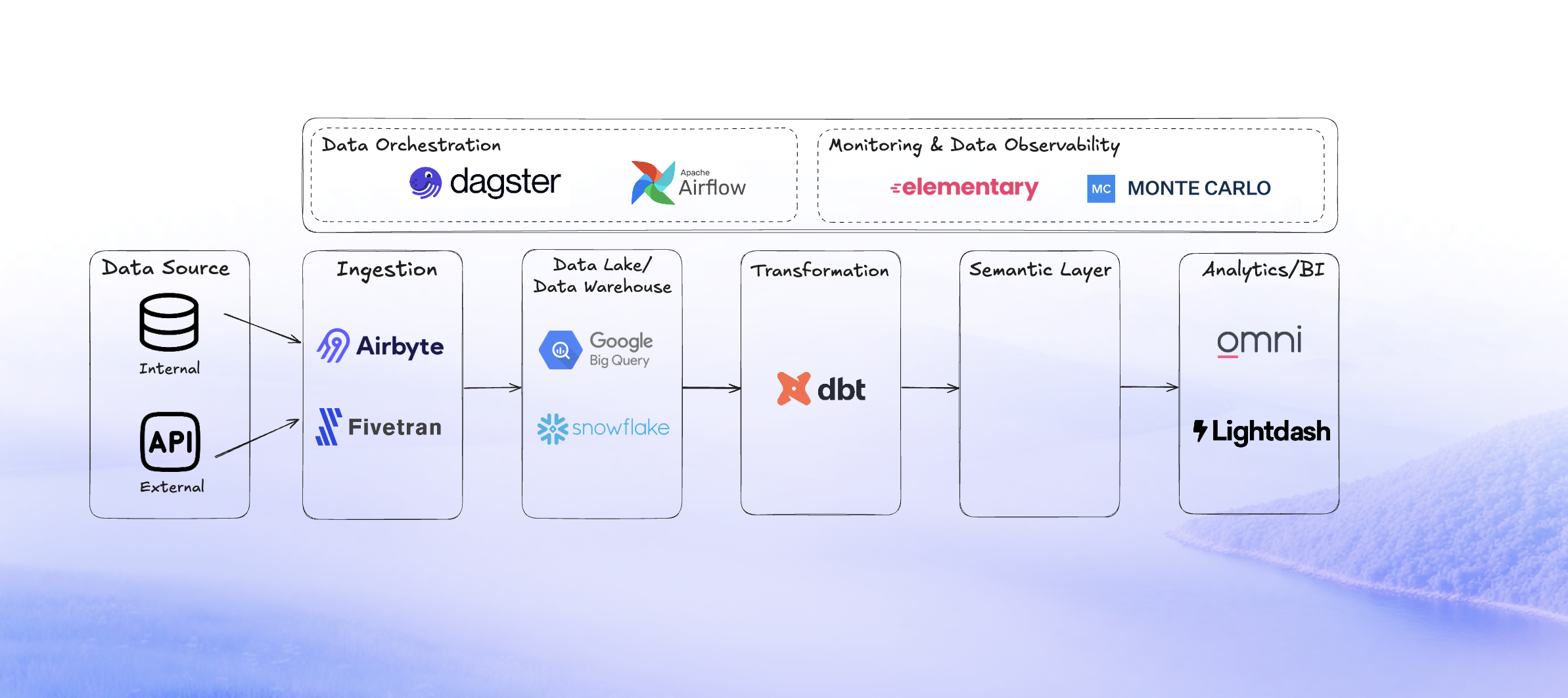
At a high level, the core components of a Modern Data Stack follow the data processing flow: ingestion, transformation, and exposure.
The following diagram illustrates this lifecycle and the different building blocks of the stack:

How to Assemble Your Data Stack
There's no one-size-fits-all Modern Data Stack. The right setup depends on your company size, data maturity, and AI ambitions.
The key is to start simple, then grow modularly as your data capabilities evolve.
1. Starter Stage (early-stage startup)
Focus on the essentials: a warehouse, transformation layer, and BI tool. Use the AI data editor nao to speed up your development cycles.
This setup gives you reliable data flows without heavy infrastructure.

2. Scaling Stage
As data volume and team size increase, introduce orchestration, monitoring, and self-serve BI. These layers bring reliability, automation, and accessibility, ensuring your stack scales smoothly.

BI tools Omni and Lightdash sit on top of dbt, providing a semantic layer that ensures consistent metrics and version control, and scale smoothly with your dbt project and data stack. New to dbt? Our step-by-step dbt setup guide walks you through your first models with AI assistance.
Data observability tool Elementary is dbt-native and monitors dbt models with automated tests and quality metrics, while enterprise-grade Monte Carlo tracks pipelines end-to-end, detects anomalies, and alerts teams to keep data reliable.
3. Mid-Enterprise Stage
At this stage, focus on consistency, governance, and collaboration. Add a semantic layer to standardize business definitions, and include data catalog and governance tools to maintain data quality and compliance. As data volumes grow, enterprises can also move from a data warehouse to a data lake to handle large, diverse datasets.

4. Data as Code (DaC) Stack
If you want to fully mange your stack as code - and make it easier for AI agents to manage it for you, you can move to code-based configurations, defining pipelines and transformations directly in code instead of manual clicks. When your stack is code-first, deploying a production-ready analytics agent becomes significantly faster — the context layer your agent needs is already documented and versioned.
This gives you more control, automation, and versioning, making your workflows faster, reproducible, and AI-ready.

Conclusion
The right data stack depends on your company's size, data maturity, and long-term goals.
- Begin with the core building blocks - warehouse, transformation, BI.
- Add orchestration, observability, semantic layers, and cataloging as you scale.
- Focus on fit and workflow, not trends or tool popularity.
- And remember, AI data editor nao can automate setup and workflows so data teams spend more time on insights - not maintenance.
A well-designed data stack grows with you - simple at the start, powerful as you evolve.

Claire
For nao team
Frequently Asked Questions
Related articles
product updates
We're launching the first Open Source Analytics Agent Builder
We're open sourcing nao — an analytics agent framework built on context engineering. Here's our vision for what comes after black-box BI.
product updates
Launching nao Context Engineering skills
Five open-source skills that set up your nao project, write its rules, build its test suite, audit it, and add a semantic layer. Install with `nao skills add getnao/nao`.
Community
Agentic Analytics Meetup Paris 🇫🇷
Recap of the first meetup dedicated to agentic analytics: 4 data teams from Gorgias, Malt, GetAround, and The Working Company share what they've actually built, what worked, and what didn't.