Why data teams need an open framework for context engineering
Analytics agents won't scale without a proper context stack. Here's why context engineering needs its own open framework — and what that framework looks like.

14 February 2026
By ClaireCo-founder & CEORemember when your company connected their BI tool directly to the production database? Figures were always wrong. Nobody trusted the dashboards — so we built data stacks to fix that.
AI agents today are the equivalent of those BI tools plugged to a production database. Every company now has internal AI agents plugged on raw context sources: data warehouses, Notion, Slack, email. It kind of works, but you can't fully trust the answers.
The problem isn't the model, the prompt, or the UI. It's that we're plugging agents directly into raw sources and expecting them to figure it out.
No curation. No governance. No structure. Just "connect your warehouse and go."
We've been here before.
This is the BI-on-production-database moment of AI.
The analogy that explains everything
In the early days of analytics, companies pointed BI tools directly at production databases.
It technically worked. You could write SQL, get some charts, call it a day.
But it didn't scale:
- Queries were slow
- Definitions were inconsistent
- Different dashboards showed different numbers for the same metric
- Nobody trusted the data
The reason? There was no governed layer between the raw database and the decision-maker.
So we built the modern data stack — ingestion, transformation with dbt, a warehouse, a semantic layer, BI tools on top. It took a decade, but we got there. (If you're still assembling your stack, the modern data stack guide breaks down every layer by company stage.)
The core insight was simple: you need a governed, structured layer between your raw data and your consumers.
Today, we're making the exact same mistake with agents.
We plug LLMs directly into warehouses, Slack, Notion, catalogs, documentation. We let them search everything and hope they pick the right source, the freshest doc, the correct definition.
When they don't — and they usually don't — we blame the model or the vendor.
But the model isn't the problem. The missing context stack is.
Context governance: the new data governance
We needed data governance because without it, "revenue" meant three different things depending on who you asked. Marketing counted gross bookings. Finance counted net ARR. Product counted active subscriptions. No metric layer, no canonical definition — every dashboard told a different story.
Today, we need context governance for the same reason. Ask "what's our refund policy?" and the answer depends on which doc the agent finds first — the outdated Notion page, the latest Zendesk article, or the Slack message from legal last quarter.
Company knowledge is full of inaccuracies, obsolete elements, and contradictions. Plugging an agent directly into that mess produces the same result as plugging a BI tool into a production database. We need a context layer — a single, governed, versioned source of truth for company knowledge.
What's actually missing
Every vendor makes a different bet about what context matters and stores it in their own proprietary format. Some build from a semantic model but can't touch your dbt docs. Some use tool calls with no semantic layer. Some accept markdown but ignore your data stack. None agree on a format — so your context work doesn't travel between tools.
Your metric definitions live in one tool. Your rules live in another. Your evaluation data doesn't exist at all.
The result:
- You start from scratch with every tool
- You can't port your context work
- You can't compare approaches across vendors
- You can't measure which pieces of context actually improve performance
This is the same fragmentation we had before dbt unified data transformation. Context engineering needs its equivalent.
Context engineering is a full stack
Context engineering is about creating sources of truth for all company knowledge — in a reliable, efficient way. That is exactly what data teams have been doing for data for years.
The equation is simple:
Context Engineering = Data Governance + Data Engineering + Data Science
- Governance — define which context sources are authoritative
- Engineering — ingest and consolidate them
- Science — measure and improve agent reliability
And what does "optimal context" actually mean? Four metrics that matter:
- Answer rate — the percentage of questions the agent can actually answer
- Accuracy — the percentage of answers that are correct
- Cost — LLM costs incurred per query
- Speed — how fast the agent responds
The trade-off is real in both directions. Too little context and the agent hallucinates or gives up. Too much context and token costs spike — 50–100K tokens per query adds up fast — and irrelevant context dilutes the signal, confusing the model with noise.
How do you engineer it? Four moves:
- Choose which sources to include and which to exclude
- Clarify which content is the source of truth (right definition, freshest source)
- Create new context where it doesn't exist yet
- Format context so the model can parse it efficiently — modular, well-structured
Context engineering follows the same principles as data engineering: measure, iterate, optimize.
Here's what that means in terms of infrastructure. To make an analytics agent reliable, you need:
Ingestion — pulling context from warehouses, dbt repos, docs, catalogs, tickets. Not just connecting via tool calls, but curating what the agent actually needs to see.
Transformation — choosing sources of truth, resolving conflicts between definitions, structuring context efficiently. The equivalent of writing dbt models for your context.
A context layer — a governed, versioned representation of your company's knowledge. Not scattered across vendor UIs and hidden embeddings, but organized as files you can read, review, and diff.
Orchestration — keeping context fresh as schemas change, as new dbt models are added, as business definitions evolve. The equivalent of Airflow for context.
Evaluation — measuring how context changes affect agent performance. Answer rate, accuracy, cost, speed — tracked over time, tied to specific context versions.
That's a full stack.
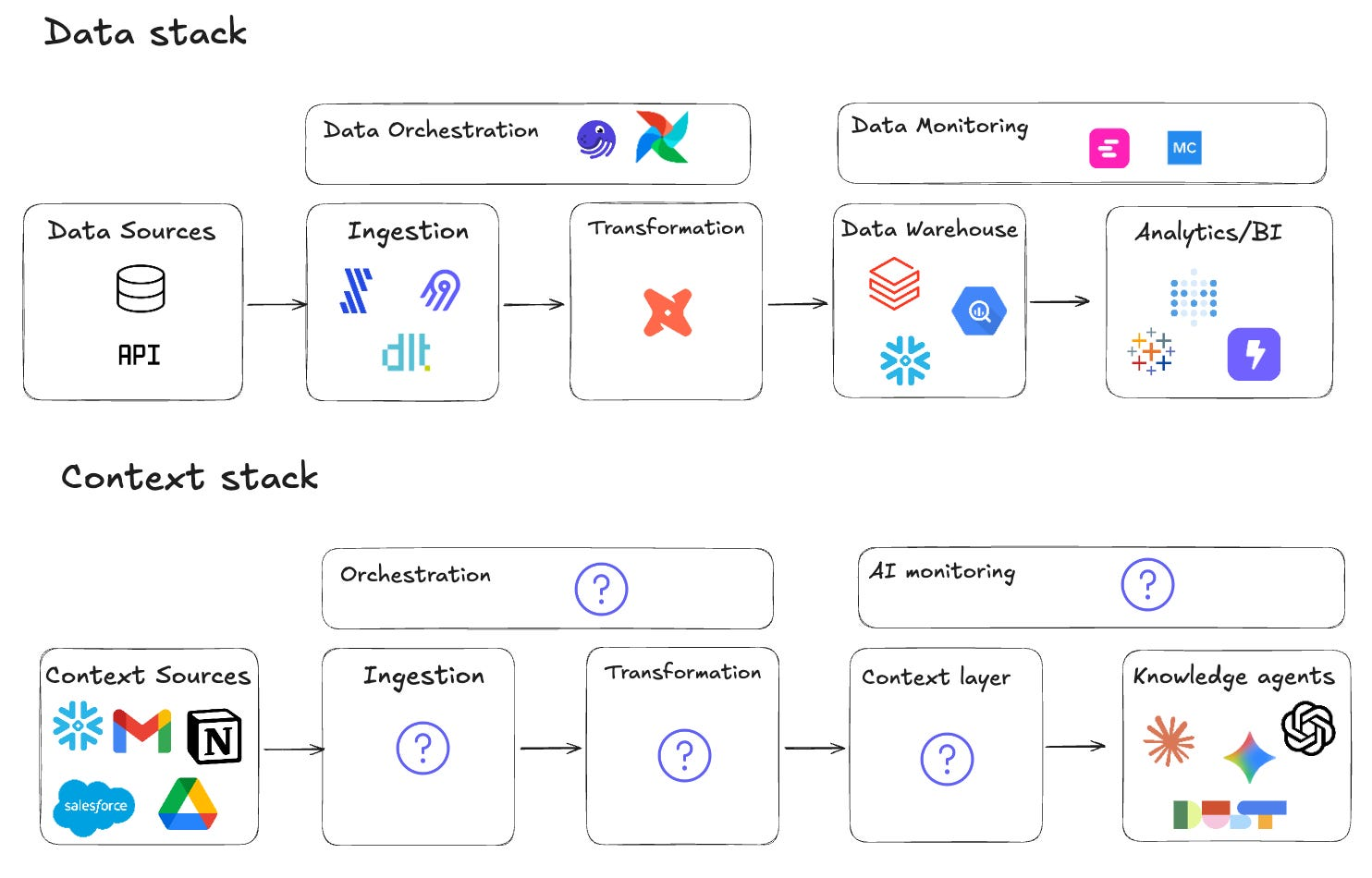
And just like the data stack, it shouldn't live inside one vendor's product.
Why closed context layers won't scale
I see three structural problems.
Debugging is impossible. When Snowflake Cortex computed our churn rate wrong, I couldn't tell if it missed the dbt description, picked the wrong table, or invented a metric. I've seen data teams spend days trying to figure out why an agent hallucinated a number — only to give up and go back to writing SQL manually.
Your work isn't portable. If you spend weeks curating definitions inside TextQL's ontology, none of that transfers to Hex or Dust or Databricks. Every tool migration = rebuilding context from scratch. Like losing your dbt project every time you change BI tools.
Nobody learns from anyone else. Every team I talk to is building the same homegrown context scripts in isolation. Great instincts, but fragile and siloed. No shared language for what a good context layer looks like. The discipline stays stuck.
What an open context framework looks like
An open framework for context engineering should look a lot like what dbt did for transformation:
Context as code. Files — markdown, YAML, configs — in a git repo. Changes tracked via PRs. Easy to inspect, diff, and version. When the agent uses a definition, you see which file it came from.
Pluggable ingestion. Connectors for warehouses, dbt, catalogs, docs. Expressed in code, not locked in a UI. Replace or extend pieces without rewriting everything.
Transparent evaluation. Test suites with expected outcomes. Metrics like answer rate, accuracy, cost, speed. Clear mapping between context versions and agent performance. Run nao test and know where you stand. The 7-step analytics agent evaluation guide explains how to build this evaluation layer in practice.
Composable with your stack. Works in CI. Plays nicely with dbt, Airflow, Dagster. Doesn't assume a single UI or model provider.
Open source at the core. So data teams can audit how context is built. So patterns and evaluation techniques can be shared. So the discipline matures through community, not lock-in.
This is what we're building with nao.
Not another analytics chatbot — an open framework for context engineering.
Context sciences: fine-tuning context like ML parameters
In ML, you define a success metric, build a labeled train/test set, tune parameters, and measure performance after each change until you find the optimum.
Context engineering should follow the same loop. Define your success metrics — reliability, cost, speed. Your parameters are the context sources, the formatting, the tools. Build a unit test set of prompts with expected answers. Change one variable, re-run the tests, measure the impact, keep what works.
The harder part is measurement. Cost and speed are easy. Reliability requires more care — do you check which files the agent cited? Run an exact data diff? Use an LLM as a judge? The right answer depends on your use case.
This is why an evaluation framework is not optional. Without it, you are tuning context blind. See our context engineering study for a concrete example of what this loop looks like in practice — 30 experiments, 40 unit tests, measurable results per context configuration.
How to start today
You don't need to wait for the ecosystem to be fully mature.
Stop treating context as a side-effect of your tools. Start modeling it explicitly. Write down your key metric definitions, your business rules, your data scope. Put them in files. Version them.
Define your first context layer. Pick a small domain — revenue metrics, a core product funnel, a specific department's KPIs. Write canonical definitions. Link them to warehouse tables and dbt models.
Build evaluation into your workflow. Turn your stakeholders' top questions into test prompts. Decide what good answers look like. Re-run when context changes. This is the single highest-leverage thing you can do for agent reliability. See How to Build Production-Ready AI Agents for a complete production checklist covering context, evaluation, and UX.
Choose tools that are inspectable. If you can't explain what context the agent used for a given answer, you're not doing context engineering — you're hoping.
Our bet: analytics agents will only be trustworthy when context engineering has an open, shared framework — just like analytics only scaled once we built the modern data stack.
The question is whether we build it together or keep reinventing fragile scripts in isolation.
I'd rather build it together. Here's where we start.
For the full launch story, read We're launching the first Open Source Analytics Agent.
For why we chose open source, see Why we're making our Analytics Agent open source.
Related articles
insights
The Agentic Analytics Playbook is out
Learn how to choose your harness, build your context layer, plan your rollout, measure success, and get examples from 7 real-life companies.
product updates
We're launching the first Open Source Analytics Agent Builder
We're open sourcing nao — an analytics agent framework built on context engineering. Here's our vision for what comes after black-box BI.
product updates
nao has a new look
We rebuilt the nao interface from the ground up. New home screen, a prompt queue, visible agent reasoning, redesigned charts and stories.

Claire
For nao team