How to do context engineering for analytics agents
A summary of 3 context engineering studies on analytics agents: what actually moves reliability, whether a semantic layer is worth it, and how to set up a testing and monitoring framework.
19 March 2026
By Claire GouzéFounder @ naoOver the past few months, I ran three studies on context engineering for analytics agents. Same data model. Same 40 unit tests. Different context setups each time.
The goal was simple: figure out what actually makes an analytics agent reliable, instead of repeating claims about semantic layers, RAG, or ontologies without evidence.
Here is what I found, and how you can apply it to your own data team.
If you want the broader framing on why data teams should own this, start with Data Teams Should Become Context Teams.
What actually moves agent reliability
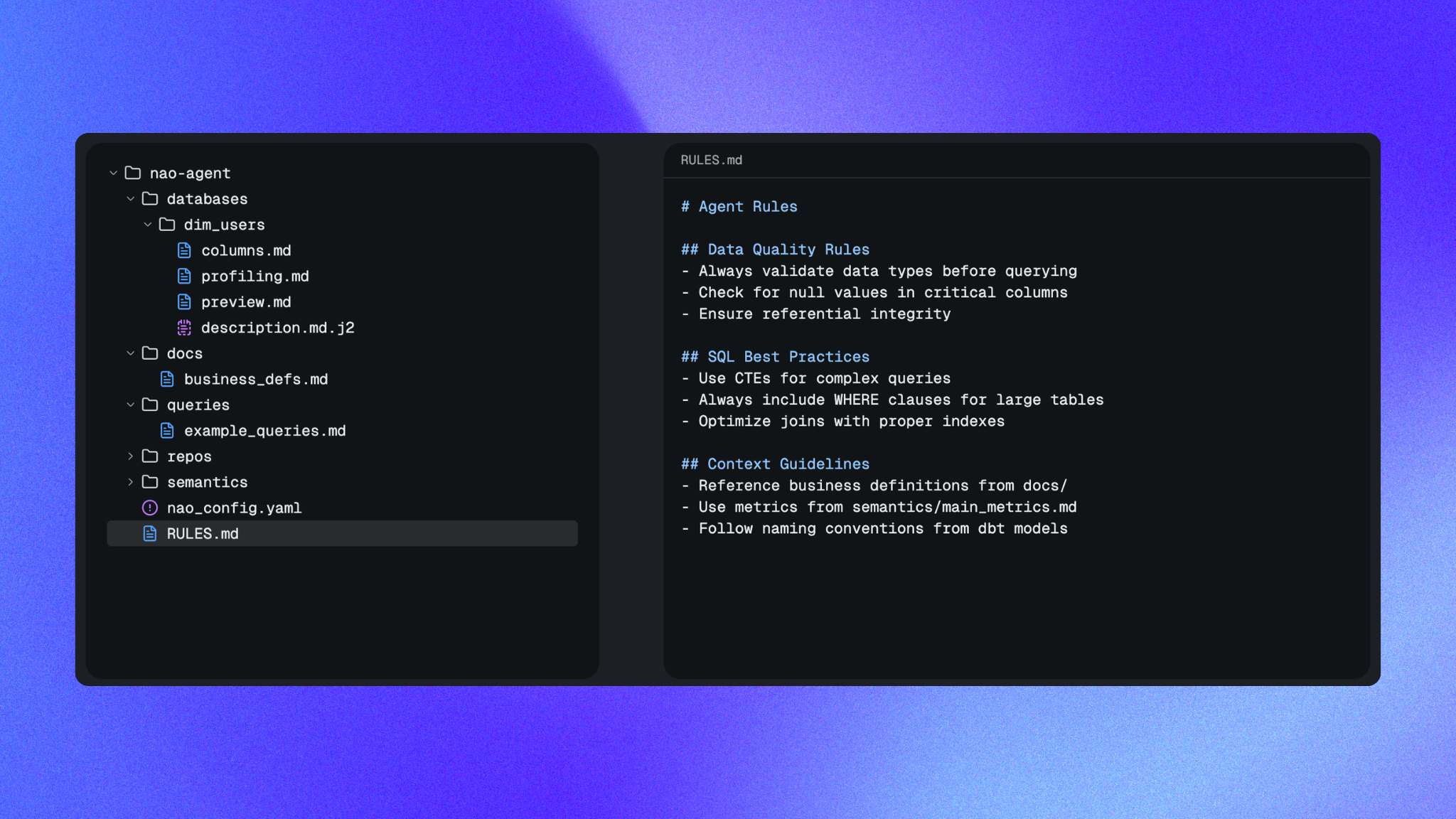
In my first study, I tested 30 different context setups against the same 40 text-to-SQL tests. The best setup reached 45% reliability. Nothing exotic. Just three pieces of context:
- data schema
- a sample of rows per table
- a
rules.mdfile with business logic and edge cases
Things that sound fancy but did not help:
- a full dbt repo pumped into context (noisy, dropped performance)
- a MetricFlow YAML as a shortcut (no improvement vs
rules.md) - a metrics-store-style semantic layer (killed coverage)
The rules.md file was the single biggest lever. Well-structured rules alone nearly matched full schema + profiling combinations. More detail on which context piece matters in Which context really improves analytics agent performance.
Then in my second study, I pushed that 45% baseline to 86% by doing failure analysis on the 28 tests that were failing. The breakdown:
- 18 data model errors
- 6 date selection errors
- 4 test errors
Fixing them in that order looked like this:
- Fix test errors (49→51%)
- Add explicit date selection rules with DO/DON'T examples (51→60%)
- Clean the data model: add missing computed fields, document metric sources of truth, clarify ambiguous terms like "our users" (65→86%)
The takeaway: context engineering is mostly data engineering. Most agent failures are data model failures in disguise. Step-by-step in How I improved my analytics agent reliability from 45% to 86%.
Should you add a semantic layer?
Short answer: not in your first pass. Maybe later, and only at scale.
In study #1, adding a dbt MetricFlow semantic layer reduced hallucinations but also reduced answers to almost zero. It was 4x more costly in tool calls and 3x slower, and the semantic YAML added no performance vs a plain rules.md.
In my third study, I tried again, this time forcing the agent to use only the semantic layer. I got it to 82% by:
- using the dbt semantic layer skill to generate it
- using the dbt natural language querying skill so the agent can pick between the semantic layer and raw SQL
- making the semantic layer exhaustive (every metric and dimension I needed in my tests)
- reviewing entities and keys manually to avoid bad joins
- enriching descriptions with business context
- adding
rules.mdrules on date filtering, null handling, ambiguous terms - adding a nao context layer so the agent doesn't rely solely on dbt MCP for discovery
More detail in Does a semantic layer improve analytics agent performance?.
My honest verdict after running it:
- the semantic layer reduces hallucinations, it doesn't remove them. The agent still has to pick the right metric among many.
- at 12 tables with clean OBT models, I hit 86% without a semantic layer and 82% with one. It's a tie.
- semantic-layer agents are more expensive and slower because of MCP tool calls.
- there is probably a complexity threshold (hundreds of tables, heavy joins) where a semantic layer starts paying off.
If you're a solo data analyst or a small team, skip it. Invest in rules.md and a clean data model first. If you run 150+ tables across multiple domains with real governance pain, it's worth the effort.
Reference patterns are in the nao rules context docs and context builder databases docs.
How to set up a testing and monitoring framework
You cannot improve what you cannot measure. This is the part most teams skip, and it's the one that compounds.
Here is the setup I use for every context change:
1. Define your success metrics. I track 5:
- coverage: % of questions the agent attempts to answer
- reliability: % of correct answers
- cost: tokens spent per answer
- speed: time to first useful response
- data scanned: volume queried against the warehouse
2. Build a unit test set. 20 to 50 real questions from your business users, each paired with the expected SQL. Store them as YAML. Cover KPI lookups, cohorts, error analysis, distributions. Mix single-table and multi-join queries. See the nao evaluation framework docs.
3. Run evaluation after every context change. Treat rules.md edits and data model changes like model releases. Re-run the tests. Diff the results. Keep what improves reliability, revert what degrades it. The full setup is in How to benchmark your analytics agent with a context stack.
4. Categorize failures, don't fix randomly. Every time a test fails, tag the root cause: data model, date scope, business ambiguity, test error, out-of-scope. This is how I found that 18 of 28 failures in my first study were data model issues, which told me exactly where to invest.
5. Monitor in production. Log user questions, agent answers, and flag runs for human review. Feed confirmed failures back into your test set. This is the loop that turns a demo into a system.
The playbook is in the nao context engineering playbook docs, and a broader view in How to build a context stack for agentic analytics.
Where to start
If you're a data team starting today:
- Write a minimal
rules.mdwith your business definitions, ambiguous-term rules, and date logic. - Add schema and a small data sample to your agent's context.
- Set up 20 unit tests based on real user questions.
- Run an evaluation baseline.
- Do failure analysis. Fix data model issues first, then rules.
- Skip the semantic layer unless you have a large, messy model.
You can get a nao project running in 5 minutes with the nao agent quickstart.
Final takeaway
Context engineering is not a tooling question. It's a discipline: clean data models, explicit rules, versioned context, and a test loop you run every time something changes.
If dashboards needed a governed data layer, analytics agents need a governed context layer. Teams that treat context like infrastructure will ship reliable agents. Teams that hope a semantic layer will fix it won't.

Claire
For nao team
Frequently Asked Questions
Related articles
product updates
We're launching the first Open Source Analytics Agent Builder
We're open sourcing nao — an analytics agent framework built on context engineering. Here's our vision for what comes after black-box BI.
product updates
Launching nao automations
Schedule your nao analytics agents to run in the background. Recurring reports, conditional alerts, and a new Feed to track all agent activity.
Buyer's Guide
LangChain vs Wren AI vs nao: which open-source tool for agentic analytics?
Three open-source projects for agentic analytics, tested on the same BigQuery question. Setup, accuracy, context approach, and which to pick.